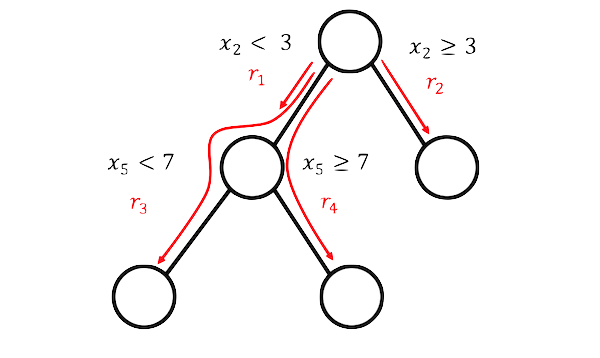
XML Preliminaries
Expert Systems (1970s & 1980s)

Transparent Machine Learning Models


Rise of the Dark Side (Deep Neural Networks)

- No need to engineer features (by hand)
- High predictive power
- Black-box modelling
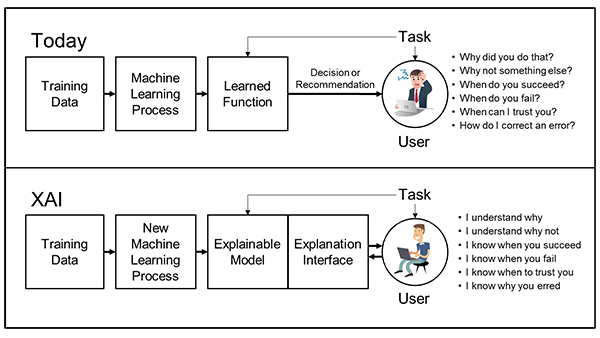
DARPA’s XAI Concept
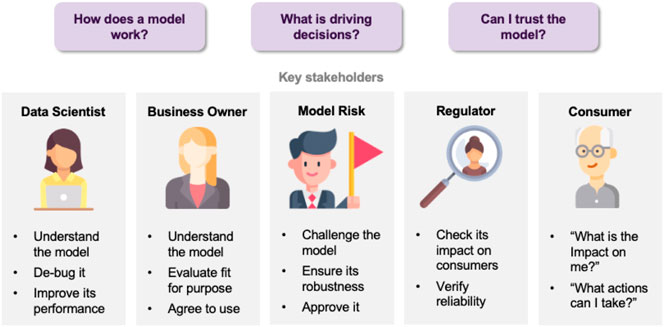
Stakeholders
Pitfalls
Copy machine study done by Langer, Blank, and Chanowitz (1978):

Explanation Domain
Original domain

Transformed domain
Where Is the Human? (circa 2017)


Exploding Complexity (2019)


Ante-hoc vs. Post-hoc

Black Box + Post-hoc Explainer
- Chose a well-performing black-box model
- Use explainer that is
- post-hoc (can be retrofitted into pre-existing predictors)
- and possibly model-agnostic (works with any black box)

Caveat: The No Free Lunch Theorem

Post-hoc explainers have poor fidelity
- Explainability needs a process similar to KDD, CRISP-DM or BigData
![Data process]()
- Focus on engineering informative features and inherently transparent models
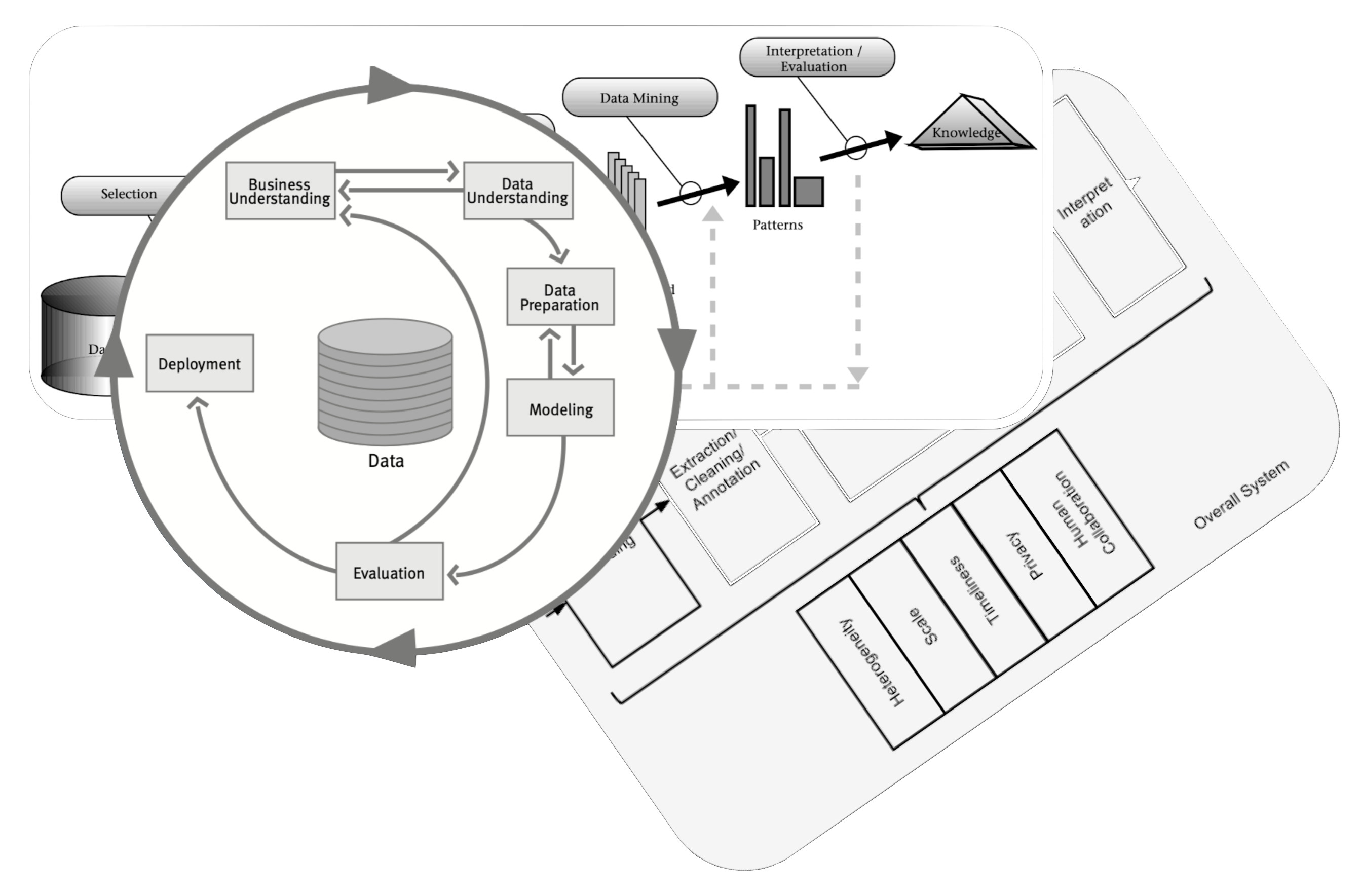
It requires effort
XAI process
 A generic eXplainable Artificial Intelligence process is beyond our reach at the moment
A generic eXplainable Artificial Intelligence process is beyond our reach at the moment
XAI Taxonomy spanning social and technical desiderata:
• Functional • Operational • Usability • Safety • Validation •
(Sokol and Flach, 2020. Explainability Fact Sheets: A Framework for Systematic Assessment of Explainable Approaches)Framework for black-box explainers
(Henin and Le Métayer, 2019. Towards a generic framework for black-box explanations of algorithmic decision systems)
![XAI process]()
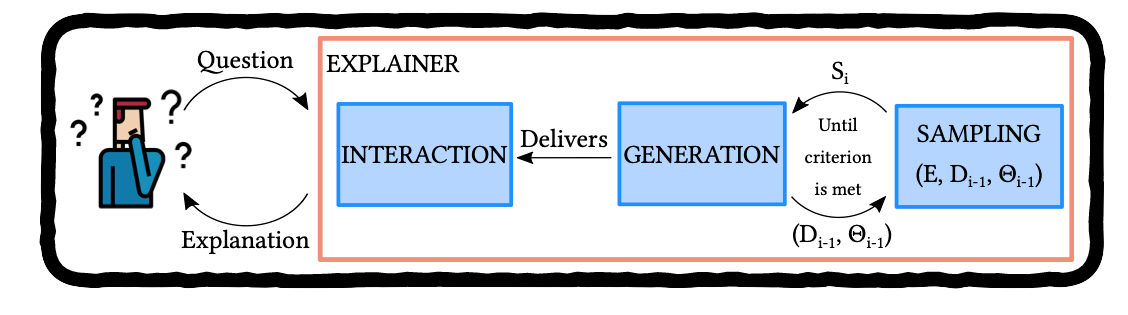
Permutation Feature Importance

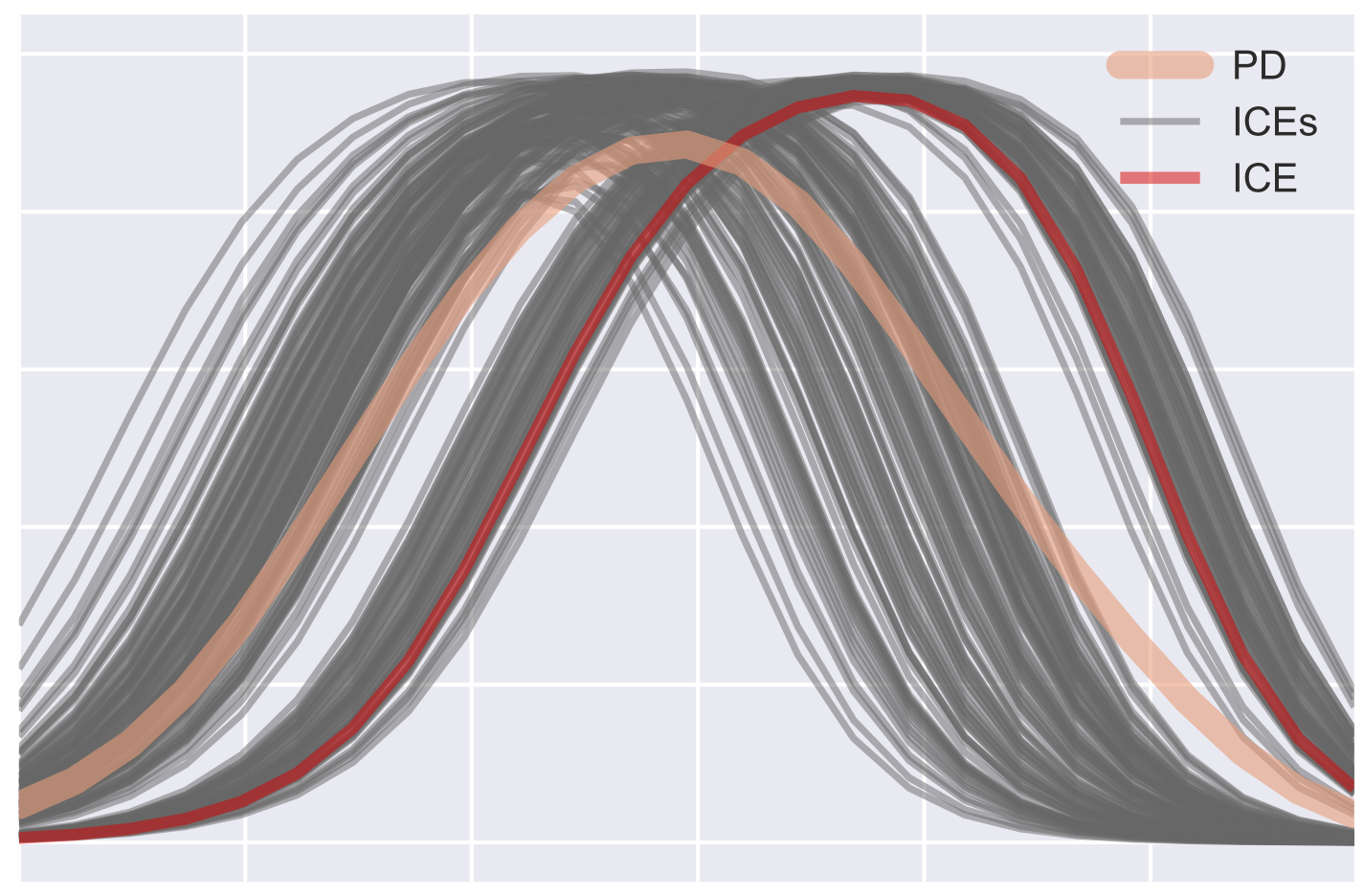
Individual Conditional Expectation & Partial Dependence
FACE Counterfactuals
RuleFit